AWS 2022 Summit - 산업 내용
요즘 엔지니어링 관련돼서 다양한 summit 및 컨퍼런스가 열립니다. 여기 페이지에는 제가 다양한 컨퍼런스에 참여해서 최신 트렌드와 동향을 파악하기 위해 글을 작성합니다.
이전 포스팅이 교육에 대한 내용이였다면, 해당 내용들은 부러움과 신기함 그리고 산업에서 실제 사용되고 있는 것들에 대한 내용이다. 이것 말고도 정말 많은 회사들이 발표하는 영상들이 있고, 발표하시는 분들이 모두 멋있게 느껴졌다.
나도 언젠간 저런 영역에서 말할 수 있겠지..? 라는 작은 꿈을 가지고 해당 내용들을 보았다.
AWS와 함께 달성한 일일 5억 건 이상의 광고 데이터 처리 노하우 - 버즈빌
예전부터 회사 내 문화부터 데이터까지 관심있게 보던 버즈빌의 영상이였다.
언제나 이런 영상을 볼때면 내용이 부럽다.
“나도 저런 분들과 같이 일할 수 있는 기회가 있었는데..” 생각하면서 말이다.
하지만 지금의 현실도 난 좋다 ㅎ_ㅎ
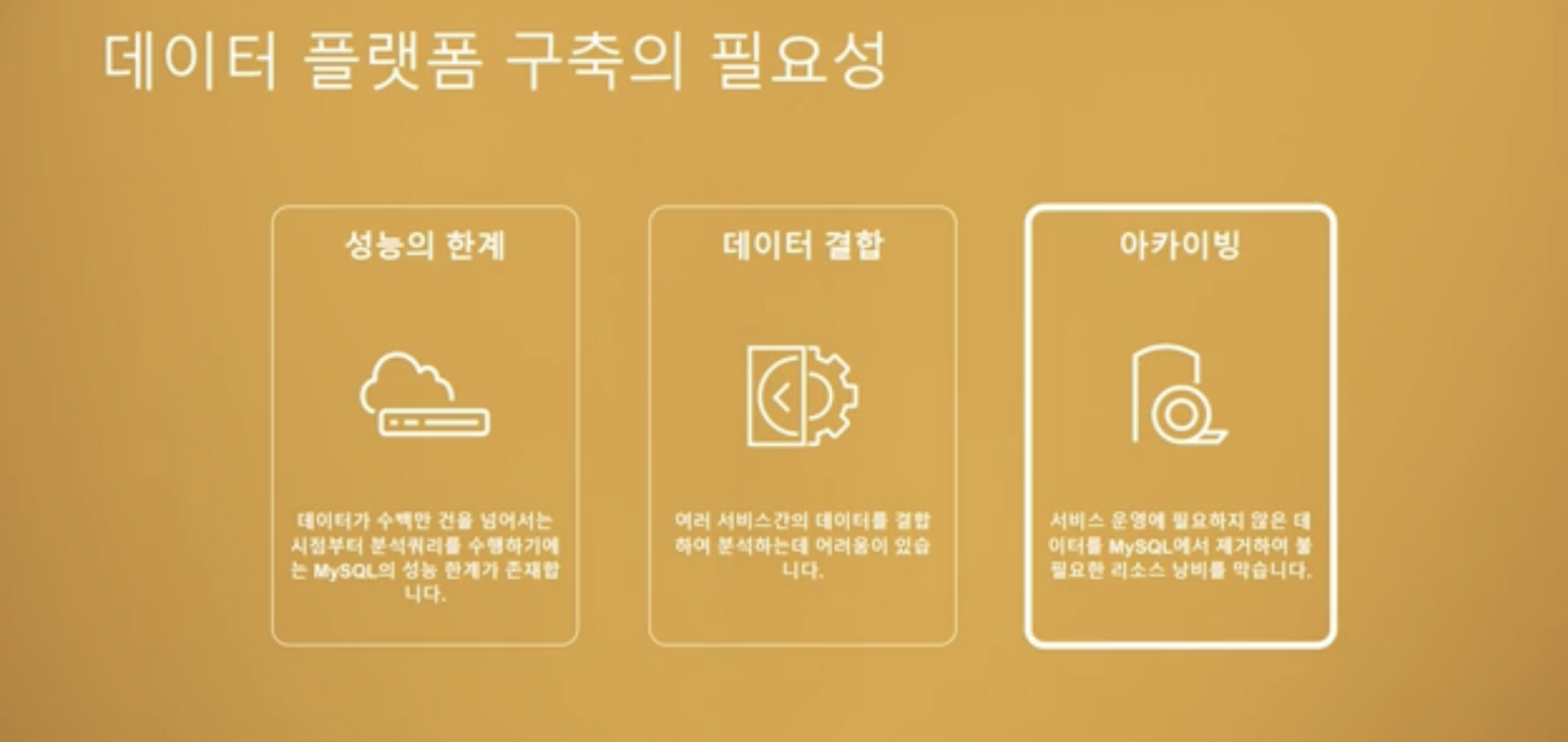
먼저 초기 버즈빌이 가진 문제점들을 말하며 내용이 시작된다.
위의 문제들로 인해서 데이터 웨어하우스 - 레드시프트를 구축해서 사용하셨다고 했다.
이 중에 인상 깊었던 내용은 다수의 MySQL 데이터베이스를 사용했기 때문에 여러 서비스의 데이터를 연결하려면 두개 이상의 데이터베이스를 연결해야하는 경우가 있었다는 것이다.


그래서 초기 데이터 파이프라인은 레드시프트와 Redash 를 통해서 구축되었다고 하신다.
- Firehose 를 통해서 대용량 데이터 전달
- RDS(MySQL)에 쌓이는 데이터 Redsfit에 전달
- 그 외 로그형 데이터는 S3 에 적재
초기에는 이렇게 진행되었다고 한다.

데이터웨어하우스 기반의 아키텍처에는 특정시간에 데이터웨어하우스에 사용이 몰리는 현상이 발생한다고 한다.
- 그래서 Redshift 클러스터의 스케일링을 조정하는 방법을 사용하셨다고함
- 이후 데이터 퀄리티를 보장하기 위해 데이터레이크로 이동을 선택

사용하실 때는 이렇게 3개의 도구를 고민하셨는데, 당시 Glue 와 Airflow 는 신뢰하기 어려운 서비스였고 운영비용과 스케일링을 고려해서 Athena 서비스를 활용하는 방식을 선택하셨다고한다.
이 부분이 인상 깊었다.
분산처리를 위해서 Airflow, EMR, Glue 방식을 선택하는 것이 일반적일 줄 알았다.
그런데 Athena 를 선택하였다니..
어느 순간부터 데이터처리에 SQL 은 어울리지 않을거라 생각했는데 SQL 은 내 생각보다 더 강했다....

데이터는 Landing 존과 Gold 존으로 나누어서 관리하셨다.
- Landing 존 : 데이터 형식에 크게 구분하지 않음
- Gold 존 : Landing 에서 정제나 집계가 이루어진 후 데이터 조회에 최적화된 Parquet 로 저장
- Gold 존에 있는 데이터를 Redshift 와 연결해서 사용
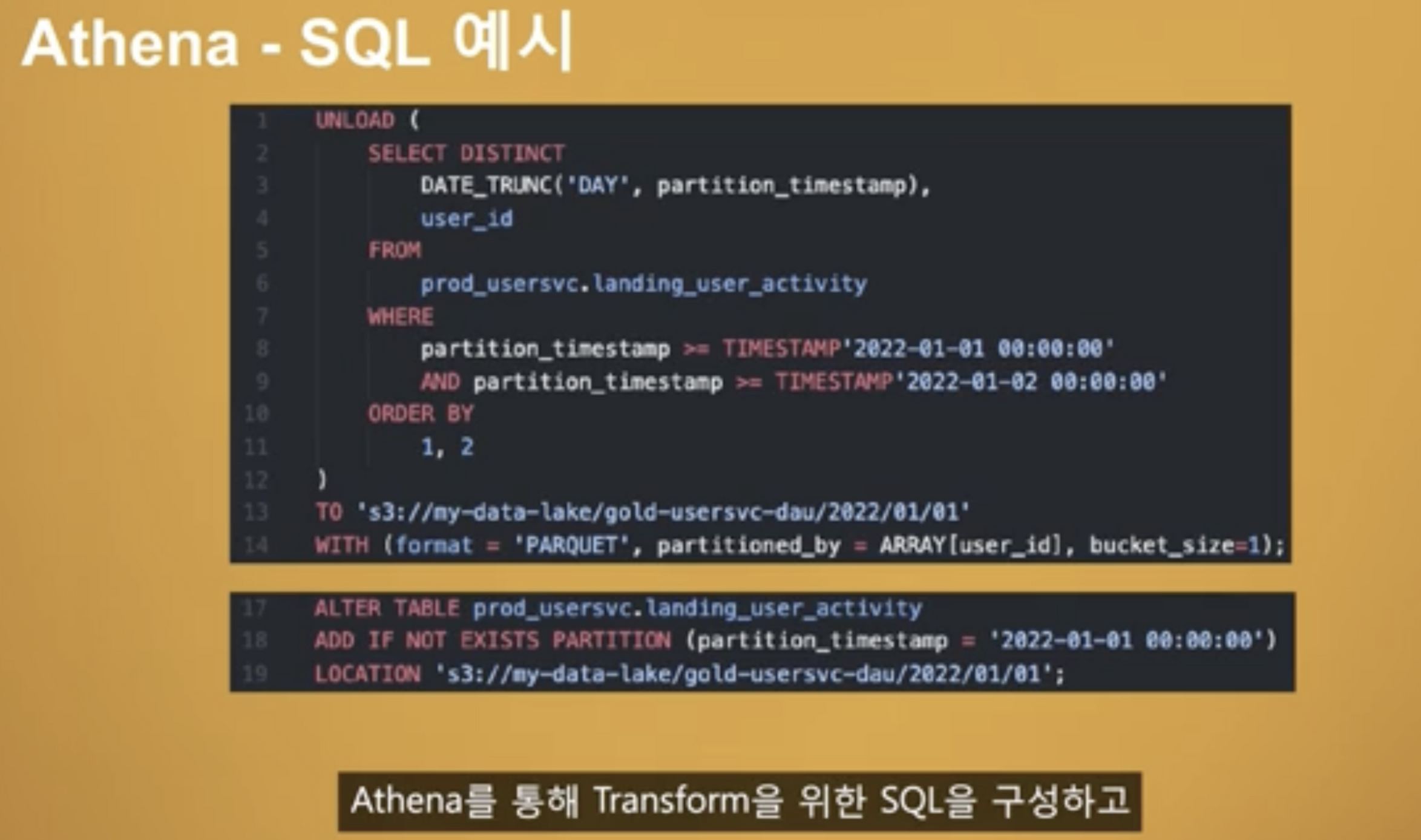
Athena SQL 예시도 같이 첨부해주셨는데 아래 네모부터 보는게 맞는거 같다.
- S3 데이터를 Athena 테이블의 파티션으로 추가하고
- Athena 를 이용해서 DISTINCT 처리 후 Gold 존에 업로드한다.
신기하였다... 나는 데이터 처리를 이렇게 SQL 로 하는건 비효율적이라고 생각했는데
산업에서는 이렇게 이용하시는 분들도 있다는게 신기하였다.
그러다가 Athena 를 AWS 에서 사용하셨을까? 라는 생각도 들었다.
왜냐면 Athena 쿼리를 실행할 때 DBeaver 나 DB 연결 도구를 사용하면 잘 안되는 문제가 있었고,
Athena 를 사용하면 SQL 관리가 잘안되었기 때문이다.
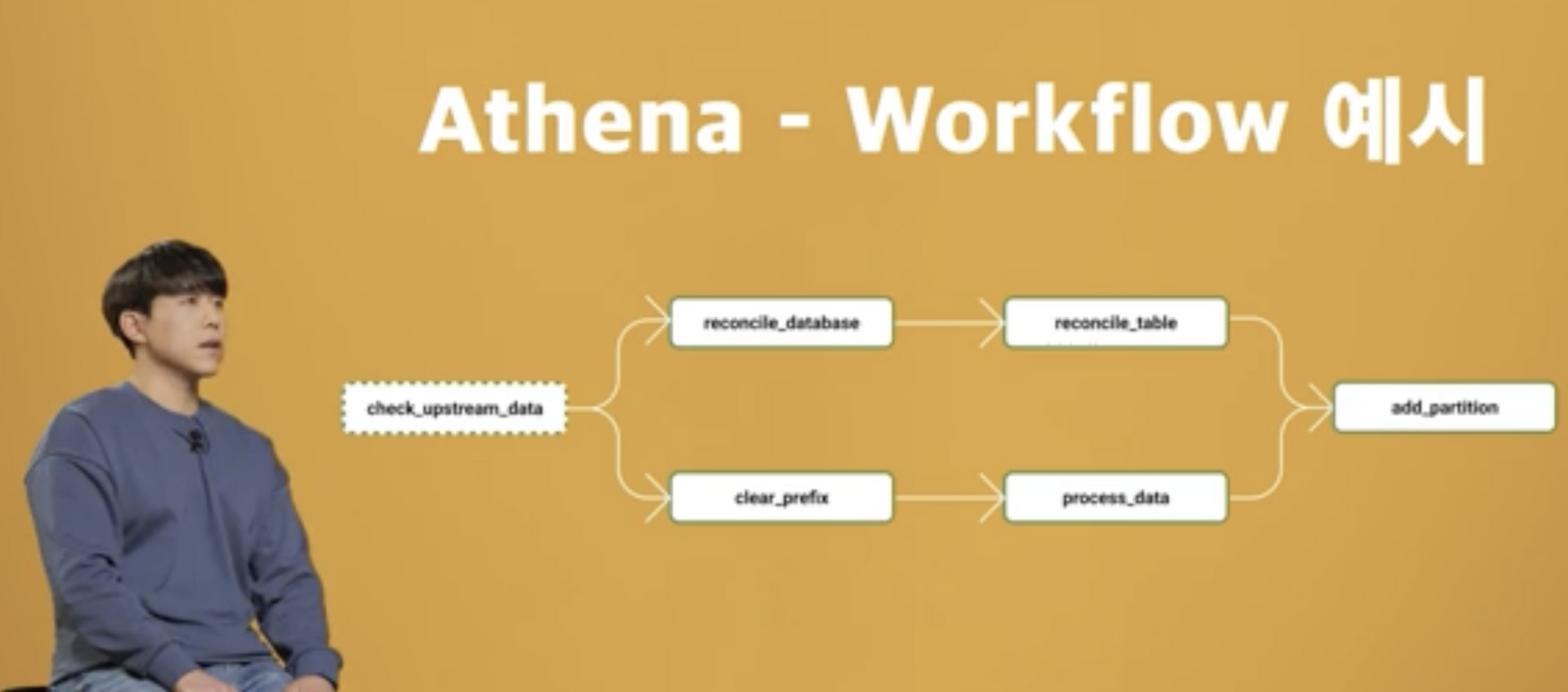
데이터레이크 진행시 고려할 점

데이터 레이크를 구성할 때 고려할 사항도 말해주셨는데
S3 에 접근에 대한 고려해야할 점이다.
- S3 는 초당 3500개의 PUT/COPY/POST/DELETE 와 5500 개의 GET/HEAD 요청 제한이 있다.
- 이는 버켓의 첫번째 prefix 에 적용된다.
이 내용은 현재 회사에서도 나오는 문제이다. 지금 회사에서는 Glue Job 을 이용해서 ETL 을 진행하는 부분이 있는데 Glue Job 에 있는 Spark 를 이용해서 S3 에 쓰기 동작을 진행할 때, Spark 내부적으로 _temp 파일을 생성한다. 그런데 이 작업이 초당 3500 번 이상이 발생하는 경우가 생겨서 Glue Job 에 문제를 일으키는 경우들이 있다...
폴더를 ‘/’ 가 아닌 대시를 통해 만든다면 문제 회피가 가능할 수도 있다.

그 다음은 S3 에 들어갈 파일의 적절한 사이즈를 선택하는 것이다.
이는 거의 업계 표준처럼 사용하는 Parquet 이다.
- S3 가 object 별로 비용이 발생하기 때문에 적절한 크기로 묶는 것이 좋다.
- parquet 파일이 너무 작으면, parquet 의 이점 중 하나인 압축을 제대로 이용하지 못하는 경우가 발생한다. 예를 들어, 너무 작은 csv 데이터를 parquet 로 변환하면 압축비율이 높지 않다.

데이터 플랫폼의 변경은 위와 같은 형태로 진행하셨다고 한다.
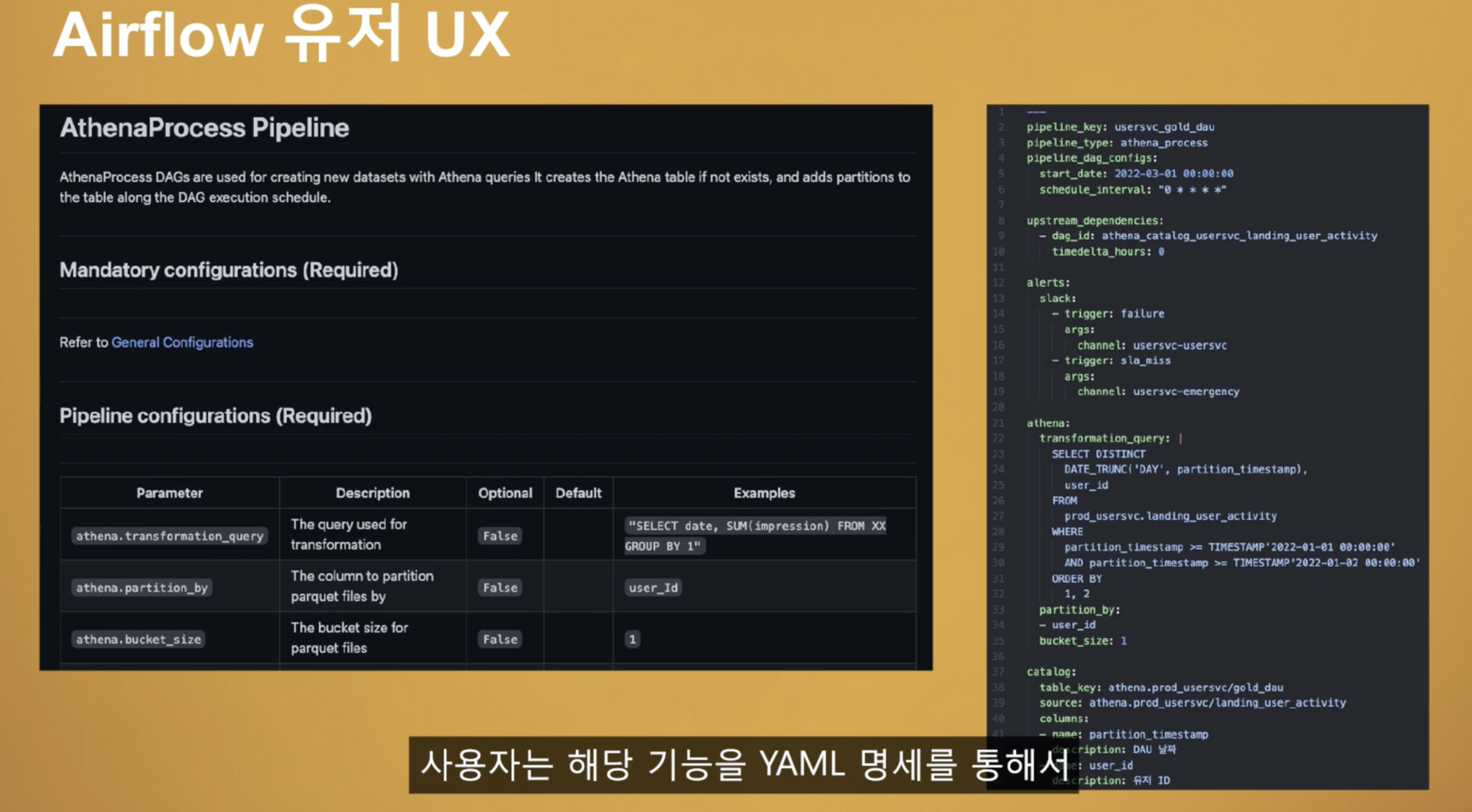
여기서 잘 몰랐던 내용은 DagFactory 패턴을 이용해서 Airflow 의 Dag 를 관리하신다는 점이다. 추후에 DagFactory 에 대한 내용도 공부하며 진행해봐야겠다...
이점이 가장 모르는 내용이었으며 스스로 공부해야할 점이라고 생각되었다.
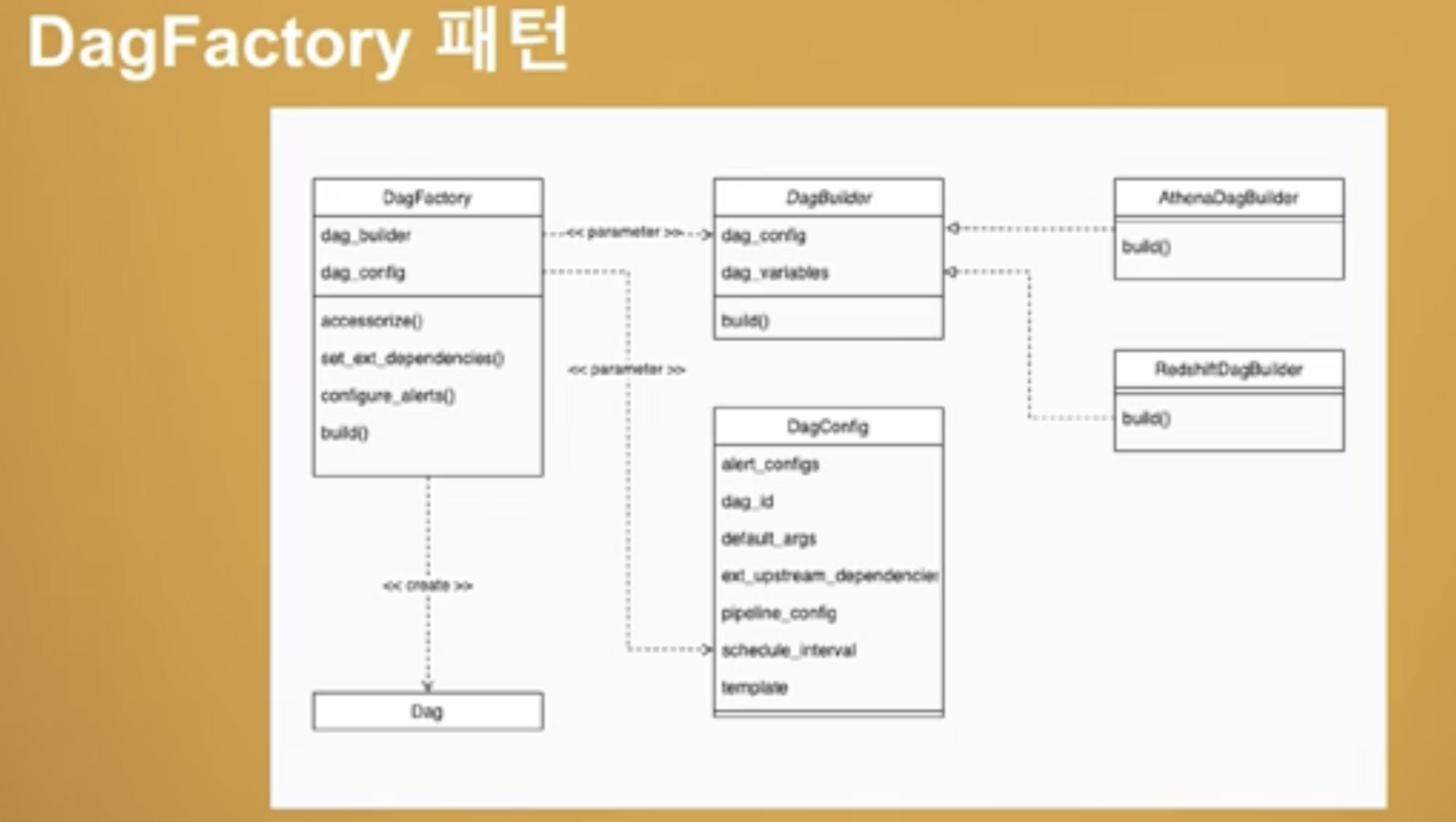
Airflow 의 설정을 관리하기 위해 yaml 파일로 관리하신다고 이해했다.
관리를 yaml 로 하신다는 점 이외에는 크게 이해하지 못했다.
나한테는 정말 고마운 영상이였다. 이전에 Redshift 를 도입해보려고 했던 기억도 나고, 스타트업 특성상 데이터엔지니어가 적어서 스스로 확신을 가지며 작업해야하는 경우가 많은데 이미 성공하신 사례를 보여주시니 내가 하는 작업들에 대해서 조금 더 확신을 가지고 진행해도 좋을거같다는 생각을 하였다.
그점에 있어서 너무 고마운 영상이였고, 진행했던 내용들에 대해서도 굵직한 내용들 위주로 너무 잘 설명을 해주셨다. 나도 내가 하는 작업들에 대해 이해가 온전히 되어 있어야 이런 영상들처럼 설명이 가능할텐데 부럽기도 한 마음이 들었다.
그 다음에는 내가 부족한 부분들을 바라볼수 있어서 감사했다. 내가 모르는 부분이 꽤나 많았다. 작게는 Athena 를 통해서 데이터 처리를 하신부분이거나, YAML 을 이용해서 Airflow 를 관리하시는 방식, Dag Factory 그리고, S3 를 통해 고려할 점들 등이 내가 앞으로 공부하고 나도 채워나가야할 부분이라고 느꼈다.
언젠간 나도 이렇게 도움이 되는 내용을 만들수 있으면 좋겠다..
그리고 이 받은 도움을 전달하고 싶다..