AWS 기반 데이터 파이프라인을 진행한다면 제일 많이 보는 것이 S3 에 데이터를 저장하고 Ahtena 로 검색을 진행하는 것이다.
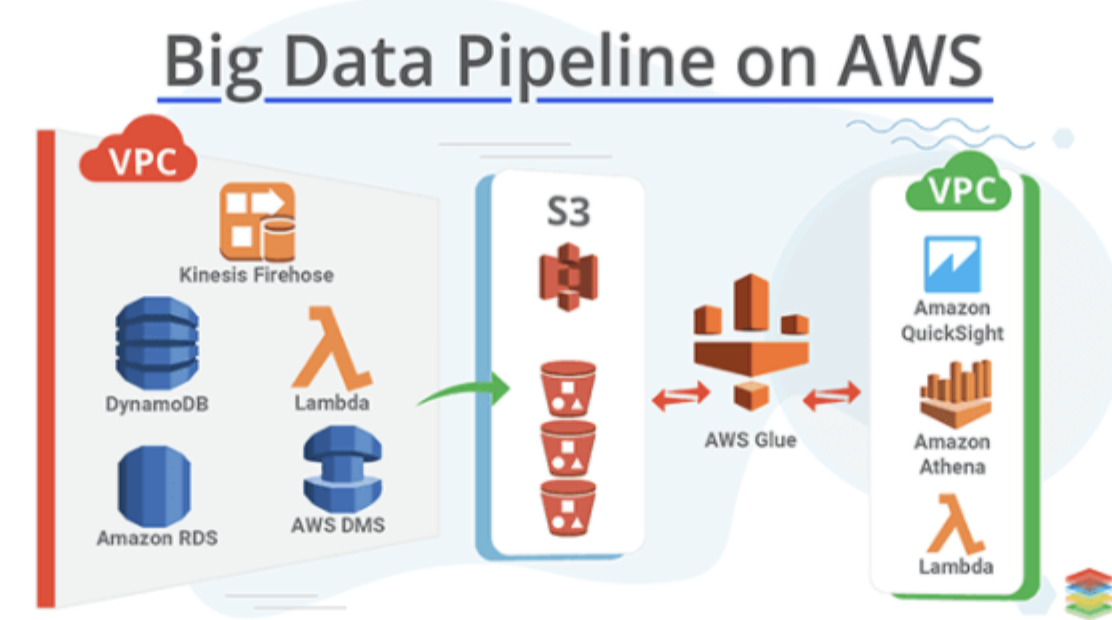
그 중에서도 이 글은 Glue Data Catalog 와 Athena 데이터베이스의 차이에 대해 설명하고자 작성하는 글이다.
왜냐하면 나도 헷갈렸기 때문이다...
좀 더 자세하게 말하자면 아래의 의문에서 해당 포스팅을 시작하였다.
“Glue 에도 Data Catalog 가 있고, Data Catalog 에 Database 가 있는데
Ahtena 에서 선택하는 Database 와 같은건가..?
이 의문을 해결하기 위해 아래의 순서로 공부하였다.
1. Ahtena 는 무엇인가?
1.1 Ahtena 는 언제 필요할까
2. AWS Glue 에서 하는 일은 무엇일까
2.1 AWS Glue Catalog 에 S3 파일이 저장되는걸까
3. Athena 와 AWS Glue Catalog 의 근본적인 차이
1. Athena 는 무엇인가?
AWS 공식문서에 따르면 “Athena 는 표준 SQL 을 사용하여 Amazon S3(Amazon Simple Storage Service)에 있는 데이터를 직접 간편하게 분석할 수 있는 대화형 쿼리 서비스” 라고 소개한다
S3 의 데이터를 간편하게 쿼리할 수 있다곤 하지만 아래의 문제는 있을 것이다.
1. S3 에 있는 모든 파일들이 바로 검색되진 않을 것이다.
2. 단순 텍스트 출력으로 파싱하기 어려운 형식이 있거나 csv, json, parquet, log 등 다양한 파일 포맷 중 지원하지 않는 파일 형식도 있을것이다.
우선, 비용은 서버리스 서비스이기 떄문에 관리할 인프라가 없고 실행할 쿼리에 대해서만 비용을 지불하면 된다.
1.1 Athena 는 언제 필요할까 ?
이것도 공식 문서 속 이야기를 빌리자면 아래와 같다
“Athena는 Amazon S3에서 데이터에 대한 지속적 메타데이터 스토어를 제공하는 AWS Glue Data Catalog 와 통합됩니다. 이렇게하면 중앙 메타데이터 스토어를 기반으로 Athena에서 쿼리 데이터를 생성합니다.”
여기까지 읽어보면 메타데이터 스토어릉 AWS Glue 의 DataCatalog 가 제공해주고 Athena 는 메타데이터스토어를 기반으로 쿼리를 진행한다는 것을 알 수 있을 것이다.
이제 그럼 Glue Catalog 의 메타데이터 스토어가 무엇인지 이어서 궁금해진다.
2. AWS Glue 에서 하는 일은 무엇일까?
이 질문은 AWS 공식문서의 Athena 하위에 “AWS Glue 통합”과 관련된 글이 있어 같이 첨부한다.
AWS Glue 는 ETL 을 제공해주는 AWS 서비스이고 AWS Glue 라는 것은 하나의 서비스라기 보단 Glue Crawler, Glue Catalog, Glue Job 등 다양한 서비스들을 통칭한다.
Athena 와 연결되는 간단하게 말하면 다음과 같다.
- S3 에 있는 객체를 Glue Crawler 를 통해 읽는다.
- Glue Crawler 는 읽은 정보를 Glue Catalog 에 저장한다.
- Athena 는 Glue Catalog 에 있는 내용을 바탕으로 쿼리를 제공한다.
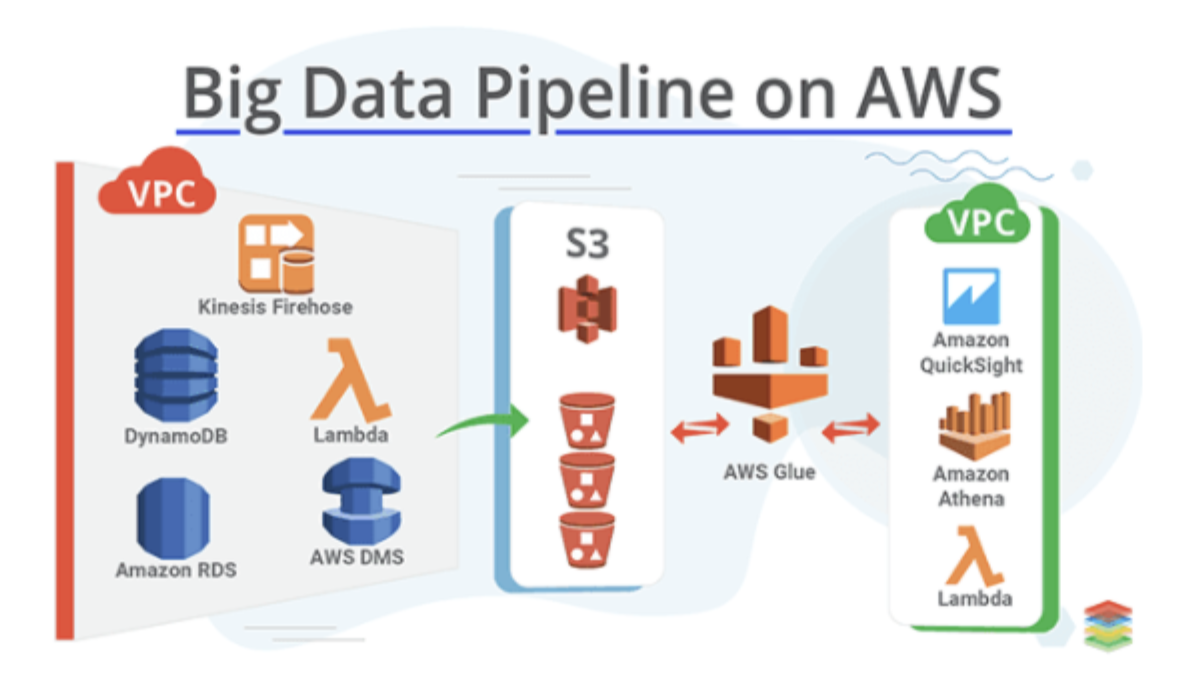
Glue 크롤러가 하는 작업을 공식문서에서 찾아보면 아래와 같다.
AWS Glue 크롤러를 사용하면 Amazon S3 의 데이터로부터 데이터베이스 및 테이블 스키마를 자동으로 추론하고 관련된 메타데이터를 AWS Glue Data Catalog 에 저장할 수 있습니다.
위에서 Glue 가 메타데이터스토어를 제공한다고 했는데 아직 메타데이터스토어에 대한 이야기는 나오지 않았다. 그래도 Glue Crawler 가 하는 일을 두가지로 정리해주었다.
- S3의 데이터로부터 데이터베이스 및 테이블 스키마를 자동으로 추론
- 추론된 내용으로부터 관련된 메타데이터를 AWS Glue Data Catalog 에 저장
이 내용으로부터 AWS Glue Catalog 에 저장되는 메타데이터를 데이터베이스 및 테이블 스키마로 예상해볼 수 있었다.
메타데이터는 S3의 어떤 데이터랑 연결되어 있고, 그 데이터의 스키마는 어떻게 구성되어 있는지로 예상된다.
이제 AWS Glue Catalog 의 메타데이터가 무엇인지까지도 감이 오기 시작한다.
그리고 Athena 가 AWS Glue Catalog 를 기반으로 쿼리를 진행한다는 것도 감이 온다.
Athena 는 쿼리를 진행하고 AWS Glue Catalog 의 스키마 정보로 검색을 진행하는 것이다.
2.1 AWS Glue Catalog 에는 S3 파일들이 저장되어 있는걸까?
아니다.
메타데이터로만 연결되어 있다는 것은 실제 데이터는 참조로만 이루어졌다라고 볼 수 있다.
그래서 만약 “S3 에 데이터가 추가되면 무조건 Glue Crawler 를 다시 실행시켜야하나요?” 라고 물어볼 수 있는데 그건 아니다. 단순히 데이터가 추가된건 참조 값이기 때문에 Athena 에서 검색할 때도 추가된 데이터가 검색될 것이다.
해당 공식문서도 참조하면 좋다.
- 위의 방식을 스키마 온 리드(Schema-on-Read) 방식이라고 한다.
- 쿼리가 시작될 때 정의된 스키마를 기반으로 데이터가 투영된다. 따라서 미리 로드할 필요가 없다.
하지만 테이블의 메타데이터가 변경되면 Glue Crawler 가 다시 시작되어야한다.
- 메타데이터가 변경되었다는 크게 3 가지를 말할 수 있다.
- 1. 파일 형태가 변경되었는지.
- 예를 들어 csv 형태의 데이터를 받다가 json 형태의 데이터를 받게된다면 메타데이터가 변경되어야한다.
- 2. 테이블 스키마가 변경할 수 있는지.
- 예를 들어 age 라는 컬럼을 받고 있지않다가 age 라는 컬럼을 받는 데이터가 많아졌다는건 스키마의 변화가 생긴 것이고, 이것이 메타데이터에 영향을 줄 수 있다.
- 3. 파티션 설정이 변경되었는지.
- 예를 들어 yyyy/mm/dd 로 파티셔닝이 되고 있었는데 값자기 yyyy에 데이터가 들어간다면 기존 파티셔닝을 깨는 문제가 생긴 것이다. 이것이 메타데이터가 변경된 것이기 때문에 해당 데이터를 읽고 싶다면 glue crawler 를 재실행해야한다.
3. Athena 는 AWS Glue 가 있기전부터 AWS 에서 제공하던 서비스이다.
여기까지 글을 쓰다가 내가 생각한 고민은 많이 해결되었다. 그리고 이 내용들이 어느정도 정리된 공식문서가 있다는 것도 확인하였다....
공식문서 나만 궁금했던게 아니기 때문에 F&Q 로 미리 정리된 문서가 있었다 ;;
그래도 추가적으로 내용을 정리했을 때 아래의 내용까지 보면 좋을 것 같다.
Athena 는 AWS Glue 가 있기 전부터 AWS 에서 S3 의 데이터를 SQL 로 조회하기 위해 사용되더 서비스이다. 이제 Glue 가 생긴 이후로 모두 Glue Catalog 로 진행할 것을 추천하고 있지만 Athena 의 데이터베이스와 Glue Catalog 를 같은 것으로 생각하지 않아야한다. 두 서비스가 현재 연결이 잘되고 있다로 생각해주면 좋다.
- AWS Glue Catalog 는 Apache Hive 를 기반으로 데이터베이스와 테이블의 정보를 구성한다.
- AWS Athena 는 Presto(PrestoDB) 를 이용해서 쿼리를 진행한다.
- PrestoDB 를 이용해서 표준 SQL 을 이용한 쿼리를 지원한다. Presto(PrestoDB) 는 쿼리 엔진이다.
그래서 이런 특징이 충돌할 수 있다.
- Presto 에서 지원하는 테이블 및 데이터베이스의 문자열은 영문 소문자, 숫자, 밑줄() 이다.
- Hive 에서 지원하는 테이블 및 데이터베이스 문자열은 대소문자, 대시(-),밑줄(),숫자이다
그렇다는 것은 Glue Catalog(Hive) 로 데이터베이스와 테이블 정보를 저장하고 있는데 Athena(Presto) 에서는 쿼리가 잘 지원되지 않을 수 있다는 것이다.
그래서 Athena 와의 연결을 고려해서 Athena 에서 지원하는
소문자, 숫자, 밑줄로 데이터베이스와 테이블 이름을 설정하는 것이 좋다.
'엔지니어링' 카테고리의 다른 글
| 리눅스 grep 명령어 (0) | 2022.05.04 |
|---|---|
| 리눅스 SED 명령어 (0) | 2022.05.04 |
| 파일 시스템 알아보기 (0) | 2022.04.15 |
| Python class 변수 , 인스턴스 변수 (0) | 2022.04.05 |
| ORM 간단하게 알아보기 (0) | 2022.04.05 |
